Backup Service
The Backup Service allows full and incremental data-backups to be scheduled, and also allows the scheduling of merges of previously made data-backups.
Overview
The Backup Service supports the scheduling of full and incremental data backups, either for specific individual buckets, or for all buckets on the cluster. (Both Couchbase and Ephemeral buckets can be backed up). The Backup Service also allows the scheduling of merges of previously made backups. Data to be backed up can also be selected by service: for example, the data for the Data and Index Services alone might be selected for backup, with no other service’s data included.
The service — which is also referred to as backup (Couchbase Backup Service) — can be configured and administered by means of the Couchbase Web Console UI, the CLI, or the REST API.
The Backup Service and cbbackupmgr
The Backup Service’s underlying backup tasks are performed by cbbackupmgr, which can also be used independently, on the command line, to perform backups and merges.
The Backup Service and cbbackupmgr (when the latter is used independently) have the following, principal differences:
-
Whereas the Backup Service allows backup, restore, and archiving to be configured for the local cluster, and also permits restore to be configured for a remote cluster;
cbbackupmgrallows backup, restore, and archiving each to be configured either for the local or for a remote cluster. -
Whereas
cbbackupmgrallows backups, merges, and other related operations only to be executed individually, the Backup Service provides automated, recurrent execution of such operations.
See cbbackupmgr, for more information.
Note that both the Backup Service and cbbackupmgr allow full and incremental backups.
Unlike the Backup Service, cbbackupmgr requires a new repository to be created for each new, full backup (successive cbbackupmgr backups to the same repository being incremental).
Both allow incremental backups, once created, to be merged, and their data deduplicated.
Both use the same backup archive structure; and allow the contents of backups to be listed, and specific documents to be searched for.
Backup-Service Architecture
The Backup Service has a leader-follower architecture. This means that one of the cluster’s Backup-Service nodes is elected by ns_server to be the leader; and is thereby made responsible for dispatching backup tasks; for handling the addition and removal of nodes from the Backup Service; for cleaning up orphaned tasks; and for ensuring that global storage-locations are accessible by all Backup-Service nodes.
If the leader becomes unresponsive, or is lost due to failover, the Backup Service ceases operation; until a rebalance has been performed. During the course of this rebalance, ns_server elects a new leader, and the Backup Service resumes, using the surviving Backup-Service nodes.
Plans
The Backup Service is automated through the scheduling of plans, defined by the administrator. A plan contains the following information:
-
The data of which services is to be backed up.
-
The schedule on which backups (or backups and merges) will be performed.
-
The type of task to be performed: this can either be one or more backups, or one or more backups and one or more merges. Backups can be full or incremental.
Repositories
A repository is a location that contains backed up data. The location must be accessible to all nodes in the cluster, and must be assigned a name that is unique across the cluster. A repository is defined with reference either to a specific bucket, or to all buckets on the cluster. Data from each specified bucket will be backed up in the specified repository.
A repository is defined with reference to a specific plan. Once repository-definition is completed, backups (or backups and merges) are performed of the data in the specified bucket (or buckets), with the data being saved in the repository on the schedule specified in the plan.
Inspecting and Restoring
The Backup Service allows inspection to be performed on the history of backups made to a specific repository. Plans can be created, reviewed and deleted. Individual documents can be searched for, in respositories.
Data from individual or selected backups within a repository can be restored to the cluster, to a specified bucket. Document keys and values can be filtered, to ensure that only a subset of the data is restored. Data may be restored to its original keyspace, or mapped for restoration to a different keyspace.
Archiving and Importing
If a repository no longer needs to be active (that is, with ongoing backups and merges continuing to occur), it can be archived: this means that the repository is still accessible, but no longer receives data backups.
An archived repository can be deleted, so that the Backup Service no longer keeps track of it. Optionally, the data itself can be retained, on the local filesystem.
A deleted repository whose data still exists can be imported back into the cluster, if required. Once imported, the repository can be read from, but no longer receives data backups.
Avoiding Task Overlap
Although the Backup Service allows automated tasks to be scheduled at intervals as small as one minute, administrators are recommended typically not to lower the interval below fifteen minutes; and always to ensure that the interval is large enough to allow each scheduled task ample time to complete before the next is due to commence; even in the event of unanticipated network latency.
Each running task maintains a lock on its repository. Therefore, if, due to an interval-specification that is too small, one scheduled task attempts to start while another is still running, the new task cannot run.
For example, given a repository whose plan defines two tasks, TaskA and TaskB:
-
If a new instance of TaskA is scheduled to start while a prior instance of TaskA is still running, the new instance fails to start.
-
If, on a cluster with a single Backup-Service node, a new instance of TaskB is scheduled to start while an instance of TaskA is still running, TaskB is placed in a queue, and starts when TaskA ends.
-
If, on a cluster with multiple Backup-Service nodes, a new instance of TaskB is scheduled to start while an instance of TaskA is still running, TaskB is passed to a different node from the one that is running TaskA, but then fails to start.
In cases where data cannot be backed up due to a task failing to start, the data will be backed up by the next successful running of the task.
Specifying Merge Offsets
As described in Schedule Merges, the Backup Service allows a schedule to be established for the automated merging of backups that have been previously accomplished. This involves specifying a window of past time. The backups that will be merged by the scheduled process are those that fall within the specified window.
The window’s placement and duration are determined by the specifying of two offsets. Each offset is an integer that refers to a day. The merge_offset_start integer indicates the day that contains the start of the window. The merge_offset_end integer indicates the day that contains the end of the window. Note that these offsets are each measured from a different point:
-
The merge_offset_start integer is measured from the present day — the present day itself always being specified by the integer 0.
-
The merge_offset_end is measured from the specified merge_offset_start.
This is indicated by the following diagram, which includes two examples of how windows may be established:
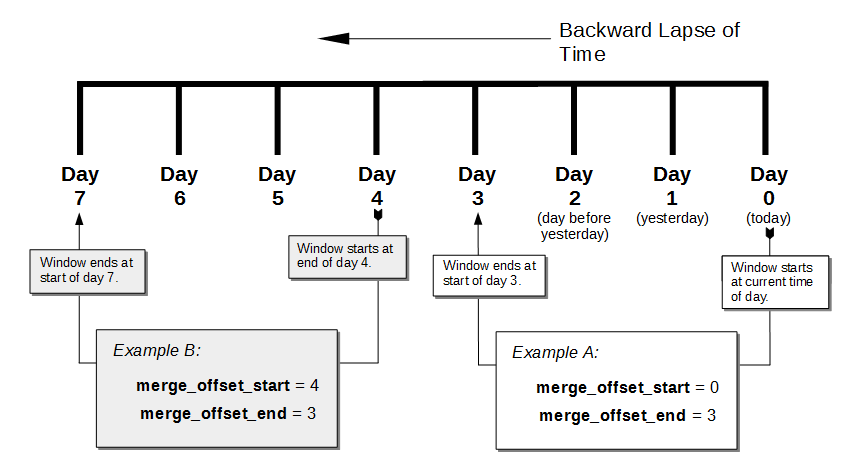
The diagram represents eight days, which are numbered from right to left; with the present day specified by the integer 0, yesterday by 1, the day before yesterday by 2, and so on. (Note that the choice of eight days for this diagram is arbitrary: the Backup Service places no limit on integer-size when establishing a window.)
Two examples of window-definition are provided. The first, Example A, shows a value for merge_offset_start of 0 — the integer 0 indicating the present day. Additionally, it shows a value for merge_offset_end of 3; indicating that 3 days should be counted back from the present day.
Thus, if the present day is June 30th, the start of the window is on June 30th, and the end of the window on June 27th. Note that the end of the window occurs at the start of the last day: this means that the whole of the last day is included in the window. Note also that when 0 is specified, the window starts on the present day at whatever time the scheduled merge process is run: therefore, if the process runs at 12:00 pm on the present day, only the first half of the present day is included in the window. All days that occur between the start day and the end day are wholly included.
Example B shows a value for merge_offset_start of 4; which indicates 4 days before the present day. Additionally, it shows a value for merge_offset_end of 3; indicating that 3 days should be counted back from the specified merge_offset_start. Thus, if the present day is March 15th, the start of the window is on March 11th, and the end of the window on March 8th. Note that when the start-day is not the present day, the window starts at the end of that day: therefore, the whole of the start-day, the whole of the end-day, and the whole of each day in between are all included in the window.
See Also
For information on using the Backup Service by means of Couchbase Web Console, see Manage Backup and Restore. For reference pages on the Backup Service REST API, see Backup Service API. For information on the port numbers used by the Backup Service, see Couchbase Server Ports. For a list of audit events used by the Backup Service, see Audit Event Reference.