Transactions
A transaction is an atomic unit of work that contains one or more operations. It is a group of operations that is either committed to the database together, or undone from the database.
Overview
Couchbase transactions support ACID properties for protected actions on the database.
Atomicity ensures that a transaction provides all-or-nothing semantics — i.e., either all the documents modified in a transaction are committed, or none of the changes are committed. If there is a failure during transaction execution (such as the client crashing) all its changes are rolled back.
Consistency — Couchbase transactions ensure that the database moves from one consistent state to another and all derived artifacts such as indexes are updated automatically (though asynchronously from the transaction). Note that the traditional definition of consistency is not relevant as there are no foreign key constraints in Couchbase.
Isolation — Couchbase transactions guarantee that the changes made in a transaction are not visible until the transaction is committed. This is the ‘Read Committed’ level of isolation.
-
The isolation provided to transactional reads is stricter than Read Committed — it is Monotonic Atomic View (MAV). Monotonic Atomic View ensures that all effects of a previously committed transaction are observed i.e. after commit a transaction is never partially observed.
-
Lost Updates are always prevented by checking against the CAS value which behaves like an optimistic lock.
Durability is a property that ensures changes made by committed transactions are not lost if failures occur. Couchbase transactions provide tunable durability to tolerate different failure scenarios with 3 different levels:
-
majority— replicate to a majority of the replicas before acknowledging the write. This is the default level. -
majorityAndPersistActive— replicate to a majority of the replicas and persist to disk on the primary before acknowledging the write -
persistToMajority— persist to disk on a majority of the replicas before acknowledging the write.
persistToMajority provides the strongest protection from failures but is the least performant amongst the Durability levels. For more information, see Durability Levels.
| Statement Level Atomicity is provided for N1QL statements that are executed inside a transaction. This means that if a query statement fails during execution for a reason like a unique key violation that statement is completely rolled back and the rest of the transaction continues. It is as though the statement is not part of the transaction. No other work in the transaction is affected by the failure of this statement. If the query statement succeeds, it would be committed or rolled back based on the outcome of the overall transaction. |
Distributed Transactions: Multi-node and Multi-Bucket
Couchbase transactions are distributed and work across multiple documents which can reside on multiple nodes. Only nodes that contain data to be updated are affected by a transaction.
Further, these documents can belong to multiple collections, scopes, and buckets.
Operations Supported by Transactions API
Transaction APIs support:
-
Key-Value insert, update, and delete operations, across any number of documents
-
Seamless integration between Key-Value (KV) and Query DML statements (SELECT, INSERT, UPDATE, DELETE, UPSERT, MERGE) within transactions
Multiple Key-Value and Query DML statements can be used together inside a transaction.
When query DML statements are used within a transaction, request_plus semantics are automatically used to ensure all updates done (and committed if done in a transaction) before the start of the transaction are visible to the query statements within it.
Using Transactions
Consider a basic debit and credit transaction to transfer $1000.00 from Beth’s account to Andy’s account with an ACID transaction.
transactions.run((txnctx) -> {
// get the account documents for Andy and Beth
var andy = txnctx.get(collection, "Andy");
var andyContent = andy.contentAsObject();
int andyBalance = andyContent.getInt("account_balance");
var beth = txnctx.get(collection, "Beth");
var bethContent = beth.contentAsObject();
int bethBalance = bethContent.getInt("account_balance");
// if Beth has sufficient funds, make the transfer
if (bethBalance > transferAmount) {
andyContent.put("account_balance", andyBalance + transferAmount);
txnctx.replace(andy, andyContent);
bethContent.put("account_balance", bethBalance - transferAmount);
txnctx.replace(beth, bethContent)
} else
throw new InsufficientFunds();
// commit transaction - optional, can be omitted
txnctx.commit();
});The Java example above is a classic example to transfer money between two accounts. Note the use of a lambda function to express the transaction.
The application supplies the logic for the transaction inside a lambda, including any conditional logic required, and the transactions API takes care of getting the transaction committed. If the transactions API encounters a transient error, such as a temporary conflict with another transaction, then it can rollback what has been done so far and run the lambda again. The application does not have to do these retries and error handling itself.
| Use transactions only on documents less than 10 MB in size. |
For application-level transactions, create and use transactions through Couchbase SDK APIs.
Here is another example that combines the usage of key-value and query operations:
transactions.run((ctx) -> {
QueryResult qr = ctx.query(inventory, "UPDATE hotel SET price = $1 WHERE name = $2",
TransactionQueryOptions.queryOptions()
.parameters(JsonArray.from("from £89", "Glasgow Grand Central")));
assert(qr.metaData().metrics().get().mutationCount() == 1);
});For more information on distributed transactions through the SDK APIs, see:
For use-cases which need to run ad-hoc data changes, you can directly use transactional constructs in N1QL. This can be accomplished using cbq, Query Workbench, CLI, or REST API in Couchbase Server, or through SDKs.
START TRANSACTION;
UPDATE CUSTOMER SET C_BALANCE = C_BALANCE - 1000 WHERE C_FIRST="Beth";
UPDATE CUSTOMER SET C_BALANCE = C_BALANCE + 1000 WHERE C_FIRST=“Andy”;
COMMIT ;For more information on using Query statements in transactions, see SQL++ Support for Couchbase Transactions.
| Take a look at the Query Transaction Simulator which demonstrates how query statements work in transactions. |
Structure of a Transaction
Every transaction has a beginning and a commit or a rollback at the end.
Every transaction consists of one or more KV operations, and optionally one or more query statements.
Create Transaction
A transaction begins when one of the following conditions are true:
-
A transactions is started from the SDK —
transactions.run((ctx)in the example above. -
The
BEGIN TRANSACTIONstatement is executed — for example, from the Query Workbench. -
A single query transaction which implicitly starts a transaction is executed, using
transactions.query(statement)from the SDK, using Run as TX from the Query Workbench, or using thetximplicitquery parameter.
End Transaction
A transaction can end when one of the following conditions are true:
-
A commit operation is executed —
ctx.commit()in the example above. -
A rollback is executed —
ctx.rollback(), or by executing theROLLBACK TRANSACTIONstatement. -
Transaction callback completes successfully, in which case the transaction is committed implicitly.
-
The application encounters an issue that can’t be resolved, in which case the transaction is automatically rolled back.
-
A transaction expiry also results in a rollback.
Savepoint
A savepoint is a user-defined intermediate state that is available for the duration of the transaction. In a long running transaction, savepoints can be used to rollback to that state instead of rolling back the entire transaction in case of an error.
Note that savepoints are only available within the context of a transaction (for example, ctx.query("SAVEPOINT") inside the lambda) and are removed once a transaction is committed or rolled back.
Transactions and Couchbase Services
All Couchbase services only see committed data. Uncommitted transaction modifications (i.e. dirty data) are never visible to any Couchbase service.
The indexes provided by the Index, Search, and Analytics services are not synchronously updated with the commits performed by transactions, and instead they are updated with Eventual Consistency. Hence, a query performed immediately after committing a transaction may not see the effects of the transaction.
The Query Service provides the transactional scan consistency parameter, request_plus, which allows queries to wait for indexes to be appropriately updated, following a transaction. This request_plus parameter ensures that your queries operate on the latest visible data.
When a query is used inside a transaction, the transactional scan consistency is set to request_plus by default, and hence ensures that the query will see all the committed changes.
Note that you can choose to update the scan consistency level to not_bounded in some cases such as the following:
-
If your query uses USE KEYS.
-
If you know that the data being accessed or consumed by the transaction has not been recently updated.
-
If your transaction does not care about the latest data, for example UPSERT or INSERT statements.
Transactions and Replication (XDCR)
Cross Data Center Replication (XDCR) supports eventual consistency of transactional changes. No uncommitted changes will be ever sent to target clusters. Once committed, the transactional changes arrive one by one at the target. If the connection is lost midway, it is possible for the target to receive a partial transaction. Note that when using transactions and XDCR, there are different document-counts between source and target, due to the transaction metadata documents that are never replicated.
To avoid issues, using active-active bi-directional replication with transactions is not advised. For customers who do choose to use active-active bi-directional replication with transactions, transactions should not be executed on the same set of documents in the active-active clusters: the applications connected to each cluster should be responsible for creating and updating a specific set of mutually exclusive documents, identified by their keys. This also means that if a transaction fails on one cluster, the transaction should be retried on the same cluster.
Finally, when transactions are being used with XDCR, the following are strongly recommended:
-
Always follow the steps provided in Ensuring Safe Failover, to fail a transactional application from one data center to another.
Transaction Mechanics
Consider the transaction example to transfer funds from Beth’s account to Andy’s account.
Assuming that the 2 documents involved in this transaction live in two different nodes, here are the high-level steps that the transaction follows:
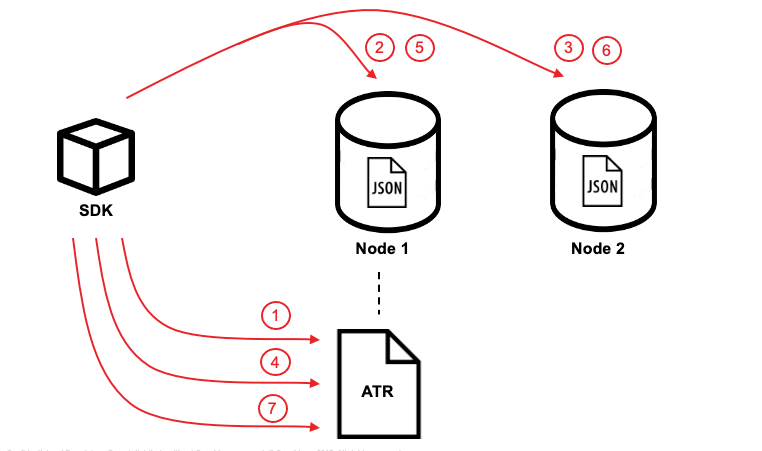
Each execution of the transaction logic in an application is called an 'attempt' inside the overall transaction.
Active Transaction Record Entries
The first mechanic is that each of these attempts adds an entry to a metadata document in the Couchbase cluster. These metadata documents are called Active Transaction Records, or ATRs.
ATRs are created and maintained automatically and are easily distinguishable by their prefix _txn:atr-. They are viewable and should not be modified externally.
Each ATR contains entries for multiple attempts. Each ATR entry stores some metadata and, crucially, whether the attempt has been committed or not. In this way, the entry acts as the single point of truth for the transaction, which is essential for providing an 'atomic commit' during reads. In Step 1 above, a new entry is added to the ATR.
By default, the metadata documents are created in the default collection of the bucket of the first mutated document in the transaction. However, you can choose to use a named collection to store metadata documents. See Custom Metadata Collections for details.
Staged Mutations
The second mechanic is that mutating a document inside a transaction, does not directly change the body of the document. Instead, the post-transaction version of the document is staged alongside the document — technically in its extended attributes (XATTRs). In this way, all changes are invisible to all parts of the Couchbase cluster until the commit point is reached.
These staged document changes effectively act as a lock against other transactions trying to modify the document, preventing write-write conflicts.
In Steps 2 and 3 in the illustration above, the transaction id and the content for the first and second mutations are staged in the XATTRs of their respective documents.
Cleanup
There are safety mechanisms to ensure that leftover staged changes from a failed transaction cannot block live transactions indefinitely. These include an asynchronous cleanup process that is started with the creation of the Transactions object, and scans for expired transactions created by any application, on all buckets.
Note that if an application is not running, then this cleanup is also not running.
The cleanup process is detailed in Asynchronous Cleanup.
In Steps 4 and 5 in the illustration above, the documents “userA” and “userB” are unstaged, i.e., removed from xAttrs and replaced with the document body.
Committing
Only once the application logic (lambda) has successfully run to conclusion, will the attempt be committed. This updates the attempt entry, which can be used as a signal by transactional actors as to whether to use the post-transaction version of a document from its XATTRs. Hence updating the ATR entry is effectively an 'atomic commit' switch for the transaction.
After this atomic commit point is reached, the individual documents are committed (or "unstaged"). This provides an eventually consistent commit for non-transactional actors (including standard Key-Value reads). Transactions will begin reading the post-transactional version of documents as soon as the ATR entry is changed to committed.
In Step 4 in the illustration above, the transaction attempt is marked as “Committed” in the ATR and the list of document ids involved in the transaction is updated.
In Step 7 in the illustration above, the transaction attempt is marked as “Completed” and is removed from the ATR.
Permissions
To execute a key-value operation within a transaction, users must have the relevant Administrative or Data RBAC roles, and permissions on the relevant buckets, scopes and collections.
Similarly, to run a query statement within a transaction, users must have the relevant Administrative or Query & Index RBAC roles, and permissions on the relevant buckets, scopes and collections.
Refer to Roles for details.
|
Query Mode
When a transaction executes a query statement, the transaction enters query mode, which means that the query is executed with the user’s query permissions.
Any key-value operations which are executed by the transaction after the query statement are also executed with the user’s query permissions.
These may or may not be different to the user’s data permissions; if they are different, you may get unexpected results.
|
Custom Metadata Collections
By default, metadata documents are created in the default collection of the bucket of the first mutated document in the transaction.
The metadata documents contain, for documents involved in each transaction, the document’s key and the name of the bucket, scope, and collection it exists on.
In cases where deployments need a more granular way of organizing and sharing data across buckets, scopes, and collections, a custom metadata collection with appropriate RBAC permissions can be used to control visibility. You can also use a custom metadata collection if you wish to remove the default collection.
To define a custom metadata collection, use the following configuration parameter:
Transactions transactions = Transactions.create(cluster,
TransactionConfigBuilder.create()
.metadataCollection(metadataCollection));When specified:
-
Any transactions created from this Transactions object, will create and use metadata in that collection.
-
The asynchronous cleanup started by this Transactions object will be looking for expired transactions only in this collection.
For more information, see Custom Metadata Collections in the Transactions API documentation.
Implications When Using Transactions
-
The number of writes required by a transactional update is greater than the number required for a non-transactional update. Thus transactional updates may be less performant than non-transactional updates.
Note that data within a single document is always updated atomically (without the need for transactions): therefore,whenever practical, design your data model such that a single document holds values that need to be updated atomically.
-
Non-transactional updates should not be made to any document involved in a transaction while the transaction is itself in progress. In certain cases, the interaction can interfere with the integrity of the transactional updates; in other cases the interaction can cause the non-transactional update to be overwritten.
-
When using Query statements in a transaction, we recommend that you limit the number of mutations within a transaction as the delta table grows with every mutation resulting in increased memory usage. Use the “memory-quota” setting in the query service to manage the amount of memory consumed by delta tables.
For ETL-like loads or massive updates that need ACID guarantees, consider using single query transactions directly from the Query Workbench, CLI, or cbq. Single query transactions, also referred to as implicit transactions, do not require a delta table to be maintained.
Deployment Considerations
If using a single node cluster (for example, during development), then note that the default number of replicas for a newly created bucket is 1. If left at this default, then all durable Key-Value writes, which are used by transactions, will fail with a DurabilityImpossibleException. This setting can be changed via GUI or command line. If changed on a bucket that already exists, the server needs to be rebalanced.
Use of transactions requires Network Time Protocol (NTP) to be used to synchronize time across all cluster-nodes. See Clock Sync with NTP for details.
Settings and Parameters
Transactions can be configured using a number of settings and request-level parameters.
| Parameter | Description |
|---|---|
Durability level |
|
Scan consistency |
|
Request-level Query parameters |
Request-level parameters when using queries within transactions. See N1QL Transactions Settings for details. |
Transaction expiry timer |
Configures how long a transaction should last before it is rolled back. The transaction expiry timer (which is configurable) will begin ticking once the transaction starts. The default value is 15 seconds. Within this timeframe, if there are concurrency or node issues, a combination of wait and retry operations are used until the transaction reaches this time. For more information, see Transactions Error Handling. |
tximplicit |
Specifies that a DML statement is a singleton transaction. By default, it is set to false. See tximplicit for details. |
kvtimeout |
Specifies the maximum time to wait for a KV operation before timing out. The default value is 2.5s. See kvtimeout for details. |
atrcollection |
Specifies the collection where the active transaction records (ATRs) and client records are stored. The collection must be present. If not specified, the ATR is stored in the default collection in the default scope in the bucket containing the first mutated document within the transaction. See atrcollection for details. |