Data Service
The Data Service provides access to data.
Understanding the Data Service
The Data Service is the most fundamental of all Couchbase services, providing access to data in memory and on disk.
All JSON data-items must be encoded as specified in RFC 8259. Binary data-items can have any encoding.
The memory allocation for the Data Service is configurable. The Data Service must run on at least one node of every cluster.
The architecture of the Data Service is illustrated as follows:
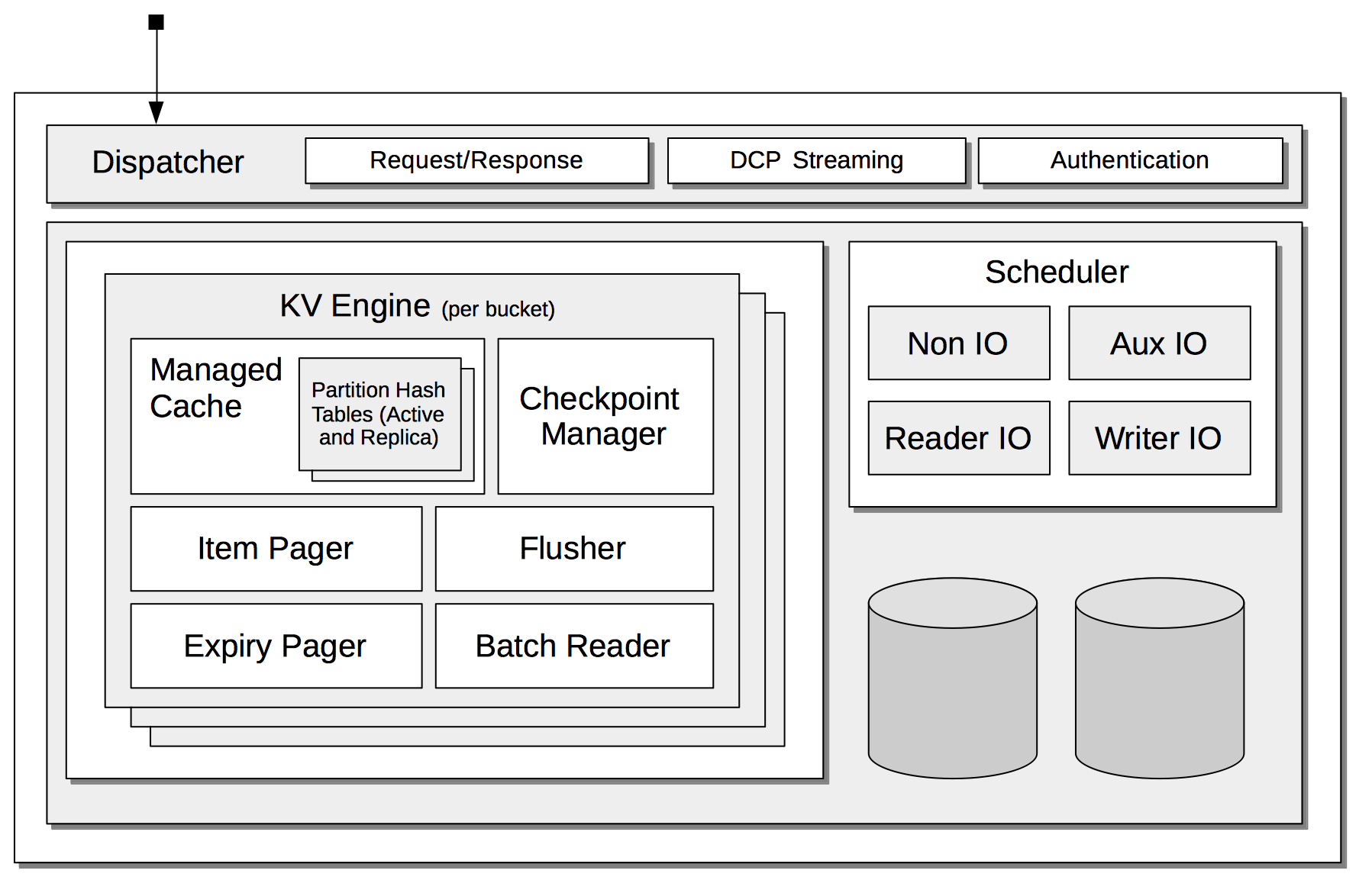
The principal components are:
-
Dispatcher: Manages networking, by handling each Request for data, and providing the Response. Also streams data to other nodes within the cluster, and to other clusters, by means of the DCP protocol; and handles Authentication.
For information on DCP Streaming, see Clusters and Availability. For information on Authentication, see Authentication. For information on ports used by the dispatcher, see Network Configuration.
-
KV Engine: A collection of facilities that is provided for each bucket on the cluster. These are:
-
Managed Cache: The memory allocated for the bucket, according to an established quota. This contains Partition Hash Tables, whereby the location of bucket-items, in memory and on disk, on different nodes across the cluster, is recorded. When written, items enter the cache, and subsequently are placed onto a replication queue, so as to be replicated to one or more other nodes; and (in the case of items for Couchbase buckets) onto a disk queue, so as to be written to disk.
For information on memory quotas, see Memory. For information on how items from a bucket are assigned to vBuckets across a cluster, see vBuckets. For illustrations of how items are written and updated for Couchbase buckets, see Memory and Storage.
-
Checkpoint Manager: Keeps track of item-changes, using data structures named checkpoints. Changes already made to items in memory, but not yet placed on the replication and disk queues, are recorded.
-
Item Pager: Ejects from memory items that have not recently been used, in order to free up space, as required. For further information, see Memory.
-
Flusher: Deletes every item in the bucket. For information on how to activate, see Flush a Bucket.
-
Expiry Pager: Scans for items that have expired, and erases them from memory and disk; after which, a tombstone remains for a default period of 3 days. The expiry pager runs every 10 minutes by default: for information on changing the interval, see
cbepctlset flush_param. For more information on item-deletion and tombstones, see Expiration. -
Batch Reader: Enhances performance by combining changes made to multiple items into batches, which are placed on the disk queue, to be written to disk.
-
-
Scheduler: A pool of threads mainly used for handling I/O. The threads are divided into four kinds, which run independently of and without effect on one another:
-
Non IO: Tasks private to the scheduler that do not require disk-access; including connection-notification, checkpoint removal, and hash-table resizing.
-
Aux IO: Fetch, scan, and backfill tasks.
-
Reader IO: Threads that read information from disk.
-
Writer IO: Threads that write information to disk.
For more information on the Data Service' threading model, see Storage Properties.
-